
Фахівці підрозділу DeepMind компанії Google розробили і випробували роботу свого роду прискорювача процесу самонавчання і пізнавання для розроблюваних ними систем штучного інтелекту.
Цей прискорювач отримав назву агент UNREAL (Unsupervised Reinforcement and Auxiliary Learning) і його робота вже була перевірена на 57 найпростіших іграх для комп’ютера Atari і середовищі тривимірного лабіринту Labyrinth, яка налічує 13 рівнів.
Ліем Танг (Liam Tung), розповідаючи про агента UNREAL, вказав, що в основу його роботи були закладені ті ж самі принципи пізнавання і самонавчання, які свого часу дозволили штучного інтелекту здобути перемогу над Лі Сеголен, світовим чемпіоном з давньої китайської гри Го. А створювався цей агент з метою прискорення робота алгоритмів штучного інтелекту і нейронних мереж, що розробляються співробітниками підрозділу DeepMind.
“Наші самонавчається вже домоглися значних успіхів в грі Го і в іграх для старих комп’ютерів” – пишуть дослідники в офіційному блозі DeepMind, – “Проте, на їх підготовку, початкове навчання і подальше самонавчання витрачається занадто багато часу”.
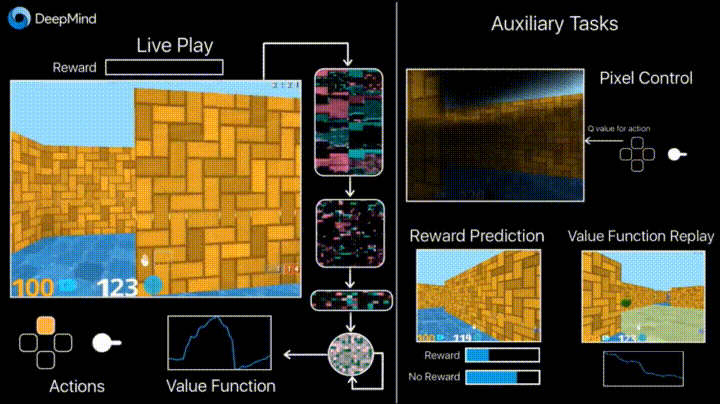
Прорив в швидкості самонавчання і пізнавання був досягнутий за рахунок впровадження в алгоритм двох нових ключових моментів, двох процесів. Першим моментом є вивчення того, як ті чи інші дії зачіпають відображається на екрані комп’ютера зображення, яке є єдиним типом даних, що подаються на вхід систем штучного інтелекту. “Раніше в процесі навчання наші системи вчилися прогнозувати, до чого може привести ту чи іншу дію. Тепер же система буде достовірно знати це з достатньою точністю. Цей новий процес вельми нагадує те, як дитина вчиться керувати своїми руками, рухаючи ними і спостерігаючи за результатом “.
Другим моментом, який пришвидшує процес навчання, є можливість повторного аналізу вже відбулися ситуацій, в ході яких системою був придбаний той чи інший досвід. “Це схоже на те, як людина іноді прокручує у себе в голові деякі з моментів комп’ютерних ігор, в яких йому вдалося досягти успіху або зробити бажану дію. При цьому людина схильна згадувати і ті моменти, коли їм було отримано негативний результат і негативний досвід”.
“Зараз наш агент обігрує середньостатистичної людини на 880 відсотків в найпростіших комп’ютерних іграх. А при вирішенні більш складних завдань в тривимірному лабіринті, він показує 10-кратне збільшення швидкості самонавчання і середнє 87-процентну перевагу над людиною, демонструючи в деякі моменти часу воістину надлюдські можливості “.
В найближчому часі фахівці DeepMind планують адаптувати агента UNREAL до дій в більш складній навколишньому середовищу, ніж найпростіші комп’ютерні ігри і тривимірні лабіринти. А це, в свою чергу, дозволить використовувати може швидко навчатися системи штучного інтелекту в реальному світі для вирішення реальних завдань.
Leave a Reply
Щоб відправити коментар вам необхідно авторизуватись.