Британські вчені розробили комп’ютерний алгоритм, який дозволяє штучним нейромереж навчатися, зберігаючи «пам’ять» про попередній досвід.
В даний час глибокі штучні нейромережі є одним з найбільш перспективних варіантів реалізації машинного навчання. Так, алгоритми, навчені подібним чином, краще за інших справляються з розпізнаванням зображень і освоєнням настільних ігор. Тим не менш, вони як і раніше значно поступаються біологічним аналогам: зокрема, глибокі нейромережі не здатні зберігати придбані раніше навички при навчанні новим завданням. Цей феномен, який отримав назву «катастрофічною забудькуватості» ( catastrophic forgetting ), унеможливлює послідовну тренування однієї і тієї ж нейромережі на кількох завданнях.
Щоб заповнити прогалину, вчені з Імперського коледжу Лондона і компанії DeepMind запропонували використовувати метод, який дозволяє штучно підвищувати стійкість ключових переваг для першого завдання при навчанні другої. Технічно це здійснюється так: при послідовному навчанні нейромережі кожному перевазі (він визначає, наскільки той чи інший нейрон значущий для відповіді системи) додатково присвоюється параметр F, що визначає його значущість тільки для певного завдання. При цьому значення F прямо пропорційно стійкості переваги до змін. Таким чином, алгоритм зберігає «пам’ять» про найважливіші навичках, придбаних раніше.

Запропонований підхід отримав назву «пружне закріплення перевагваг» (elastic weight consolidation) за аналогією з пружиною, жорсткість якої порівнянна з параметром F. У разі нейромережі «натяг» походить від переваги, оптимального для завдання A, до переваги, оптимальному для завдання B. В внаслідок функція втрат (енергія пружини) зростає, і менш значущі переваги адаптуються до нової задачі, тоді як важливі для попередніх завдань переваги, імовірно, залишаються незмінними.
Випробування алгоритму проводилися на двох завданнях: навчанні з підкріпленням і навчанні з учителем. В останньому випадку нейросеть тренувалася розпізнавати рукописні цифри, причому автори послідовно вносили в стимули спотворення, щоб кожен новий крок вимагав навчання «з нуля». В рамках навчання з підкріпленням алгоритм навчався грати в ігри приставки Atari 2600, систематично освоюючи нові стратегії поведінки.
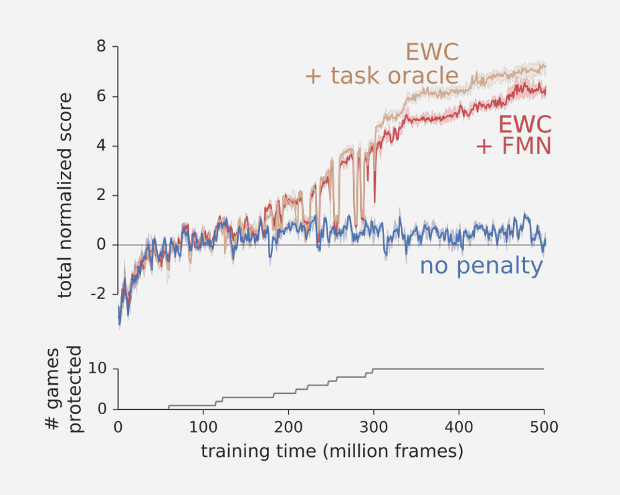
Аналіз показав, що алгоритму вдалося зберегти «пам’ять» про переваги, необхідних для виконання попередніх завдань. В кожному окремому випадку ефективність нейромережі знижувалася, проте за сумою етапів вона демонструвала хороші результати. При навчанні методом градієнтного спуску, що дозволяє видаляти переваги при тренуванні на новому завданні, алгоритм успішно справлявся з виконанням окремих етапів, але виявився не здатний задовільно відтворити минулий досвід.
Тим часом вчені активно працюють над додатком «розумних» алгоритмів до практичних завдань. Широке застосування нейромережі можуть отримати в правовій сфері. Так, напередодні дослідники навчили комп’ютерний алгоритм з відносно високою точністю розпізнавати злочинний умисел людини.
Leave a Reply
Щоб відправити коментар вам необхідно авторизуватись.